

近日,发布的最新 MLPerf Inference 基准测试 (4.0) 结果并没有令人吃惊。随着 MLPerf 继续跟上快速发展的 ML 技术的步伐,基准套件中添加了两个新的工作负载 - Llama 2 和 Stable Diffusion XL。 Nvidia 展示了 H100 和 H200 的结果,高通的 Cloud AI 100 Ultra(预览类别)和 Intel/Habana 的 Gaudi 2 显示出收益。英特尔拥有唯一的 CPU 作为加速器。
瞻博网络是首次参展,展示了网络的重要性。红帽和 Supermicro 联合提交了一份利用 OpenShift AI 的文件。云基础设施提供商 Wiwynn 是另一位新提交者。
总体而言,近年来提交者数量相当稳定。此次共有 23 家企业,其中包括 ASUSTeK、Azure、Broadcom、Cisco、CTuning、Dell、Fujitsu、Giga Computer、Google、Hewlett Packard Enterprise、Intel、Intel Habana Labs、Juniper Networks、Krai、Lenovo、NVIDIA、Oracle、Qualcomm Technologies, Inc .、广达云科技、红帽、Supermicro、司马和纬颖科技。 MLPerf Inference v4.0 包含来自 23 个提交组织的 8500 多个性能结果和 900 个 Power 结果。
由于推理加速器的粗略排序(至少目前看来已经确定),英伟达与竞争对手之间令人震惊的条形图缺失了。 Nvidia 加速计算产品总监 David Salvator 发表了更有趣的言论之一,他表示推理收入目前占 Nvidia 数据中心收入的 40%。
“推理已成为我们数据中心活动和业务的重要组成部分,”Salvator 表示,“在我们上次的财报电话会议上,我们表示它约占我们去年数据中心收入的 40%。部分原因是我们看到了这种交叉,推理正在成为更占主导地位的工作负载。 [原因]是应用程序部署后,这些应用程序通常会 24/7 运行。通过训练,你完成了一次训练,基本上就完成了,至少暂时完成了。据推断,一旦部署该应用程序,它就会一直运行,并开始消耗整个人工智能工作负载的很大一部分。”

自 2018 年推出以来,MLPerf 已稳步成为加速器市场的固定产品,虽然在此过程中可能不那么令人兴奋,但对于比较特定用例的不同配置的系统很有用。 Top500 中没有唯一的获胜者。 MLPerf 基准测试组织者 MLCommons 的执行董事 David Kanter 始终指出,要从结果中获取价值,有必要深入挖掘数据并逐个比较系统。
“对我来说,基准测试的目的是让整个行业保持一致。这有助于向买家提供信息,帮助他们做出决策并了解系统(无论是本地系统、云系统还是嵌入式系统)如何执行相关工作负载。因此,如果您想购买一个系统来运行大型语言模型推理,您可以使用基准测试来帮助指导您。与此同时,对于正在制定解决方案的行业人士来说,这些基准可以帮助我们了解如何优化如何改进,”坎特说。
“我们在这里添加了两个新的基准。它们都是生成式人工智能基准。第一个是 Stable Diffusion XL,它是文本到图像的生成。我们还添加了用于问答的 Llama 2 大型语言模型。现在,这两者都要求我们提出服务器、服务器模式以及离线模式的延迟。我想在这里强调的一件事是这张图表,显示了随着时间的推移,MLPerf 推理模型的参数计数是什么样的。你可以看到,这就像一般的人工智能一样,它很像一根曲棍球杆,放在右边。我认为在我们的第一轮 MLPerf Inference (v.5) 中,最大的模型大约有 2 亿个参数,而现在我们已经达到 700 亿个,”他说。
(第一个 MLPerf 推理结果于 2019 年发布,其中五个基准测试集中于图像分类、对象检测和机器翻译这三个任务。)
MLCommons 通过添加发布在 MLCommons 网站上的两个新基准来更深入地了解其决策过程。完成这项工作的团队组成由Intel、AMD、谷歌、英伟达、KRAI等多家公司,强化了竞争对手公司之间合作的理念。



实际上,从结果中挖掘价值需要做一些工作。在这一轮中,MLPerf 结果将在不同的平台(Tableau)上呈现,并且至少对我来说,有效使用这个强大平台有一个学习曲线。也就是说,数据就在那里。根据过去的做法,MLCommons 邀请基准测试参与者提交有关其条目的声明,这些声明放在文章末尾。
Nvidia 继续前进
Nvidia 仍然是广泛的人工智能加速器领域的王者,也是解决所有工作负载的唯一提交者。
MLCommons 通常会为媒体和分析师举行概述预简报,参与者可以对结果发表评论,但不要进行直接的竞争比较。各个公司可以自由地进行单独的简报来获得竞争分数。
英伟达从不缺乏竞争热情,在其私人简报中相对谦虚,这促使一位分析师问道:“似乎缺少一件事。您通常会展示一张幻灯片,其中包含您提交的所有不同基准的条形图,以及它们与之前的[运行]的比较以及/或与竞争对手的比较。我在这个幻灯片中没有看到这一点。那是怎么回事?”
Salvator 说:“嗯,所以结果将在 ML Commons 网站上广泛发布,我们决定在这一轮中重点关注较新的工作负载,特别是 Llama 2 工作负载 ,我们认为它真正代表了当前的状态艺术的。我们确实提交了每个工作负载,并且数字就在那里。就 Ilama 2 而言,我们确实展示了英特尔/Habana 与 Gaudi2 的竞争性提交……这是提交的其他主要加速器。坦率地说,我们还提交了一些其他以 CPU 为中心的结果,那些结果比这些要快得多。”
相反,Salvator 重点关注日益增长的推理复杂性、Nvidia TensorRT-LLM编译器的进步以及其在提升 H100 和 H200 性能 Llama 2 方面的有效性。基于 H200 的系统已进入预览类别,因为在提交时它们是他说,虽然尚未推出,但现在已经推出,并引用联想作为现已推出 H200 系统的供应商之一。

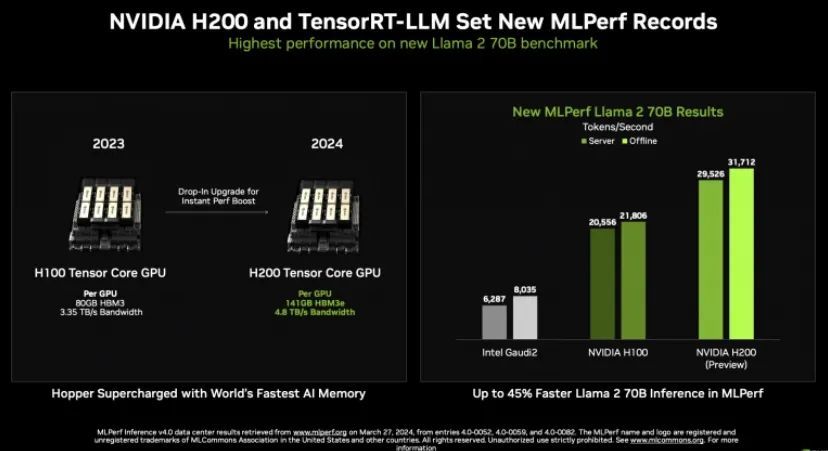

Salvator 所涵盖的大部分材料在一周前的 GTC24 会议上已被触及。他讨论了 Nvidia MGX、其使用不同机箱和热足迹的模块化参考设计以及 Nvidia 推理微服务 ( NIM )。
当被问及即将推出的 Blackwell GPU、B100 和 B200 以及它们与现有 H100 和 H200 系统的直接兼容性时,Salvator 表示:“我们并未将 B200 设计为与 H200 CTS 系统直接兼容。直接兼容方面更关注 B100,因为我们拥有相当大的 H100 基础服务器安装基础,而且我们的许多合作伙伴都知道如何构建这些服务器。因此,能够轻松更换 B100 基板的能力使它们能够更快地上市。 B200 将需要不同的底盘设计。它不会与 H200 系统直接兼容。”
英特尔/Habana 大力宣传性能和成本
近年来,英特尔已经进入 MLPerf 领域,宣传其 Gaudi 加速器系列是 Nvidia GPU 的高性能、低成本替代品,其第五代 Xeon CPU 非常适合推理或训练只占较小部分的系统。混合工作负载。
在基于最新 MLPerf 推理运行进行比较时,英特尔展示了 Gaudi 2 与 Nvidia H100 在 Stable Diffusion XL 和 Llama 2 工作负载上的性能和成本比较。
以下是英特尔供应商声明的一部分:“英特尔 Gaudi 2 加速器是一款 7 纳米处理器,为 MLPerf Inference 上最先进的模型提供了可靠的性能结果。在 Stable Diffusion XL 上,Gaudi 2 加速器的每秒离线采样数和每秒服务器查询数分别为 6.26 和 6.25,对于 Llama v2-70B,每秒离线令牌数和服务器令牌数为 8035.0 和 6287.5,分别。鉴于客户对 Hugging Face TGI(文本生成接口)的强烈需求,英特尔使用支持连续批处理和张量并行的 TGI 服务工具包提交了 Llama 结果,从而提高了实际 LLM 扩展的效率。英特尔 Gaudi 软件套件继续扩大我们最高客户需求的法学硕士和多模式模型的覆盖范围。”
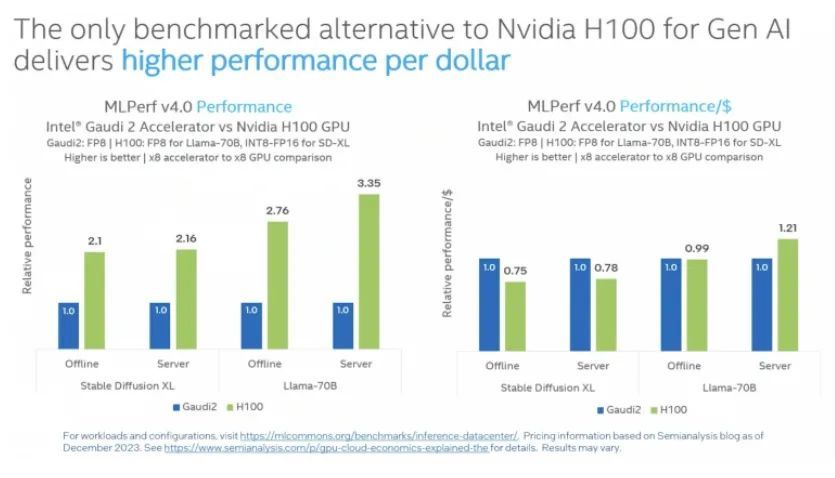
在英特尔单独的预发布会上,Habana Labs 首席工程师兼高级研究员 Itay Hubara 表示:“我们非常高兴能够提交TGIK,这是一个开源服务拥抱脸,是目前最常用的拥抱脸。服务于最高需求的社会。您可以在右侧看到基于第三方评估的价格表现标准化。我觉得这是一个公平的比较。”
他表示,成本比较是基于系统成本,而不是运营成本,但没有提供更多细节。
英特尔至强人工智能产品总监 Ronak Shah 补充道:“Gaudi 一直在跨越式发展,以实现我们提供易用性的目标,无论是通过 pytorch 等标准框架,还是在应用中利用 Hugging Faces TGI该提交使您能够获得开箱即用的性能,并通过行业中可用的标准框架提供这些类型的结果。”
这是英特尔第五代至强处理器首次出现在 MLPerf 中,Shah 展示了其与第四代至强处理器对比的结果。
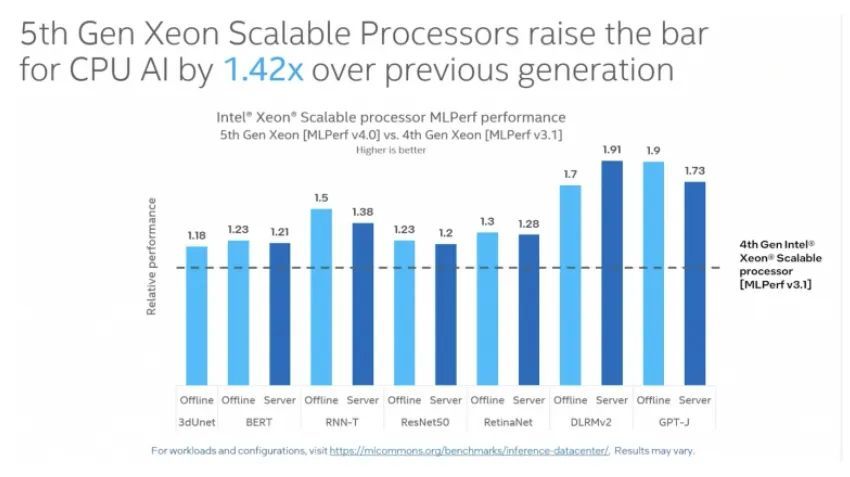
“在上面的幻灯片可以看到,与第四代至强和之前提交的产品相比,我们的性能提高了 1.42 倍。令我兴奋的是,我们在 2023 年初推出了第四代至强,并在 2023 年底推出了第五代,在一年之内,它是从第四代到第五代的硬件和增强功能的组合,以及软件优化能够将性能提高 1.42 倍。令人兴奋的是我们能够实现如此大的收益,并且我们能够真正利用一些底层架构的增强功能,”Shah 说。
沙阿指出,英特尔这次有五个合作伙伴提交了申请。 “我们有五个合作伙伴提交了申请,这一事实表明他们也认识到这就是至强的关键优势所在;当你拥有混合通用工作负载或通用应用程序并且将人工智能注入其中时,就属于这种情况。”这五个合作伙伴是思科、戴尔、广达、超微和 WiWynn。
总体而言,MLPerf 中提交的系统范围相当广泛。这里列出了一些供应商提交的声明的摘录(声明的完整列表附在下面):
瞻博网络:“对于 MLPerf Inference 4.0,瞻博网络提交了针对 Llama 2 的一套测试,该模型具有 700 亿参数的大语言模型 (LLM),该模型在瞻博网络验证设计 (JVD) 上运行,该设计由脊叶网络拓扑和轨道优化设计。多节点数据中心设置由瞻博网络人工智能优化的以太网结构提供支持,包括用于 GPU 间通信的带有 ROCEv2 的 QFX 系列交换。测试和验证是在 Juniper AI 实验室的 NVIDIA A100 和 H100 集群上进行的,具有轨内和轨间组合。这是有史以来第一次向 MLCommons 提交多节点以太网。”
高通: “在 v4.0 轮中,高通推出了人工智能推理加速器 Cloud AI 100 Ultra,并提交了‘封闭预览’模式评估。 Cloud AI 100 Ultra 的早期预览结果展示了其在低功耗下的卓越性能,其在 ML 基准测试中的性能证明了这一点。与 Cloud AI 100 Pro 提交的内容相比,所有 Cloud AI 100 Ultra 提交的内容均表现出 2.5 至 3 倍的性能提升,同时每个加速器的功耗低于 150W。除了 NLP 和计算机视觉网络之外,我们还引入了 GenAI Stable Diffusion XL 提交。我们的合作伙伴戴尔、HPE 和联想也提交了 Cloud AI 100 Ultra 卡的预览结果。”
红帽和 Supermicro:“大型 AI 数据中心基础设施建设者 Supermicro 和全球领先的企业开源解决方案提供商 Red Hat Inc 合作提交了第一个 Red Hat OpenShift AI MLPerf Inference v4.0。此提交展示了 OpenShift AI 模型服务堆栈的灵活性,可通过使用自定义运行时功能来支持 vLLM 等开源 LLM 运行时。我们还感到自豪的是,我们是本轮中唯一在 Nvidia GPU 上使用 vLLM 提交 GPT-J-6b 和 llama-2-70b 结果的结果,无需任何量化或模型编译。”
Wewynn: “在边缘类别中,我们对配备两个 NVIDIA L40S GPU 的 ES200G2 进行了基准测试,适用于图像识别或其他人工智能应用等边缘应用。在数据中心类别中,我们对配备英特尔第五代至强处理器的ES200G2进行了基准测试,该处理器可以组成服务器池来执行各种任务。这两项结果都表明该平台能够运行流行的人工智能框架并取得良好的性能。”
接下来是预计在 6 月份进行的MLPerf培训。
MLPERF 供应商提交的声明
华硕
在 MLPerf v4.0 推理基准测试中追求卓越的过程中,华硕的努力超越了单纯的性能和可靠性优化,以推进各个领域部署的人工智能技术。我们拥护社区参与的精神,认识到其在促进机器学习领域的协作、知识共享和集体进步方面的关键作用。
性能调整:与华硕 ESC8000-E11P、英特尔第四代至强可扩展处理器和 NVIDIA H100 PCIe GPU 解决方案一起,我们努力的核心是对性能优化的不懈追求。利用 GPU 服务器强大的计算能力,我们开始对基础设施的各个方面进行微调。通过细致的实验和创新技术,我们在吞吐量、延迟和效率方面取得了显着的提高。我们的解决方案经过精心设计,可充分发挥 GPU 的潜力,在现实推理场景中提供无与伦比的速度和响应能力。
可靠性增强:除了 MLperf Inference v4.0 之外,我们还非常重视增强 GPU 服务器的可靠性。认识到稳定性在关键任务应用程序中的至关重要性,我们实施了强大的机制来减少停机时间、防止瓶颈并增强容错能力。严格的测试和验证程序确保我们的基础设施在不同的工作负载和操作条件下始终提供可靠的性能。
社区参与:除了技术实力之外,我们对 MLPerf 社区的承诺也是我们成功的基石。我们积极参与知识交流论坛,贡献见解,并与同行合作推动创新向前发展。通过分享最佳实践、经验教训和从我们的旅程中获得的见解,我们为社区的集体智慧做出贡献,营造协作和共同成长的环境。
结论:在 MLPerf 4.0 推理基准领域,我们的成就不仅仅通过性能指标和可靠性基准来衡量。它们同样植根于我们对社区参与和协作精神的奉献。随着我们不断突破可实现的界限,我们对推动机器学习领域集体进步的承诺仍然坚定不移。在协作和共享知识的推动下,我们共同迈向创新无极限的未来。
博通
作为虚拟化技术的领导者,VMware by Broadcom 为全球企业提供创新的数据中心管理基础架构解决方案,帮助客户高效、安全、灵活地构建、运行和管理应用程序。对于机器学习 (ML) 和人工智能 (AI) 工作负载,我们的软件解决方案与大多数硬件供应商合作,以大规模支持这些工作负载。
Broadcom、戴尔和 NVIDIA 合作,将虚拟化的魔力引入加速器数据中心的 MLPerf Inference v4.0。除了传统基准测试之外,Broadcom、戴尔和 NVIDIA 还为新的稳定扩散(文本到图像)基准测试提交了出色的结果。我们的结果提供了接近裸机或更好的性能,并增加了数据中心管理的虚拟化优势。
我们在配备 8 个虚拟化 NVIDIA SXM H100 80GB GPU 的 Dell XE9680 和配备 2 个虚拟化 NVIDIA L40S 80GB GPU 以及 vSphere 8.02 和 NVIDIA vGPU 的 Dell R760 上运行 MLPerf 推理工作负载。我们测试中使用的虚拟机仅分配了 120 – 224 个可用 CPU 中的 32 个,以及 1T – 1.5T 可用内存中的 128 GB。我们只使用了系统容量的一小部分。因此,客户可以使用同一系统上的剩余 CPU 和内存容量来运行其他工作负载,节省 ML/AI 基础设施的成本,并利用 VMware vSphere 的虚拟化优势来管理数据中心。我们的结果与上述裸机的比较表明,配备 NVIDIA 虚拟化 GPU 的 vSphere 8.0.2 是 AIML 工作负载的最佳选择。
思科
各行各业的企业都在认识到人工智能/机器学习的真正潜力。人工智能 (AI) 和机器学习 (ML) 正在为企业解决复杂问题开辟新途径。
思科是 MLCommons 社区的新成员。思科与英特尔合作,成功提交了大型语言模型 (LLM)、图像分类(视觉)、对象检测(视觉)和语音转文本(语音)数据中心类别的 MLperf v4.0 推理结果。
思科提交了配备 Intel Xeon第五代处理器的 Cisco UCS C240 M7 服务器的推理结果。配备英特尔第五代至强可扩展处理器的思科 UCS C240 M7 服务器以 2RU 外形尺寸提供领先的性能和更高的效率,是 AI 推理的理想平台。
作为 MLCommons 社区的新成员,思科将继续支持社区为各种 AI 训练、推理和 HPC 工作负载对服务器解决方案进行基准测试的努力。在最新的MLPerf 4.0 Inference中,思科提交了在Cisco UCS C240 M7平台上使用英特尔至强第五代处理器的结果,结果表明系统在大多数推理模型中都取得了优异的性能。
CTuning
在本轮提交中,我们测试了第二代MLCommons CM-MLPerf 工作流程和CK 游乐场,以在基于 Nvidia、Intel、Amazon 和 Qualcomm 的商品硬件上自动对各种边缘服务器、笔记本电脑和云提供商(包括 AWS 和 Cirrascale)进行基准测试( 9528 中的性能结果为 8683,988 中的功率结果为 905)。
CM-MLPerf 的目标是提供单一且人性化的命令行、简单的 GUI和可扩展的 Python、C++ 和网络实现模板,以运行来自不同供应商的所有 MLPerf 推理基准测试并以统一和自动化的方式提交结果。
新版本的 CM-MLPerf 是由cTuning 基金会和cKnowledge根据上一轮提交后 MLCommons 的要求并感谢 MLCommons 成员和研究社区(ACM/IEEE MICRO'23和SuperComputing'23)的反馈而开发的。
CM-MLPerf 工作流程首次成功实现了所有边缘+数据中心工作负载(使用 llama2-7b 模型完成的 llama2 提交)以及来自 Nvidia、Intel、Qualcomm、Neural Magic 和 MLCommons 的各种实现的自动化。
我们也非常自豪能够首次使用 MLCommons CM 在云端对 Qualcomm Cloud AI 100 系统进行基准测试,并感谢 Qualcomm 的支持。我们还感谢来自英特尔、英伟达和谷歌的同事的反馈和建议。
我们邀请每个人使用和增强MLCommons CM-MLPerf 自动化,并参与一个新项目,以使用 MLPerf 和 CM作为协作工程工作,自动共同设计高性能且经济高效的 AI 应用程序和系统。
下图由CM-LPerf 浏览器插件生成,显示了我们提交系统(均使用 Nvidia RTX 4090)上边缘模型的延迟,是提交给 MLPerf 推理的最佳延迟之一。 Nvidia RTX 4090 还显示出令人印象深刻的离线和服务器性能,如我们的数据中心结果所示。
戴尔科技
戴尔凭借最广泛的 GenAI 解决方案脱颖而出,涵盖从台式机到数据中心再到云的所有内容。该公司处于人工智能发展的最前沿,戴尔PowerEdge XE服务器系列为这一变革之旅奠定了基础。
在 MLPerf 推理 v4.0 基准测试领域,戴尔科技集团通过提交各种模型的 281 个结果来展示其承诺,其中包括使用 Qualcomm、Broadcom 的 CPU 和加速器对新的 Llama2-70b、Stable Diffusion XL、GPT-J 进行的测试、英伟达和英特尔。测试涵盖了广泛的产品,展示了戴尔通过 PowerEdge 服务器系列满足不同人工智能工作负载的能力。
Dell PowerEdge XE系列,特别是配备 NVIDIA Tensor Core H100 GPU 的产品,在大型语言模型、图像分类等领域展示了卓越的性能。此外,配备 NVIDIA L4 GPU 的 PowerEdge XR5610 凸显了戴尔在系统效率方面的努力,优化了边缘工作负载的性能。
Dell PowerEdge XE 加速服务器系列在多个基准测试中继续提供巨大的性能提升。以下是一些最新亮点:
配备 8 个 NVIDIA H100 Tensor Core GPU 的 PowerEdge XE9680 继续在大语言模型、文本到图像、语音到文本、语言处理、图像分类和推荐方面提供戴尔最佳性能结果。
4 GPU 直接液冷 Dell PowerEdge XE9640 和风冷 PowerEdge XE8640 在 GenAI 模型、图像分类、对象检测、语音转文本、语言处理、摘要、医学图像分割等方面取得了出色的结果。
Dell PowerEdge XR5610 和 NVIDIA L4 GPU 针对边缘工作负载提供出色的每 GPU 功耗比系统性能
戴尔邀请客户通过在其全球客户解决方案中心进行试驾来探索这些进步,提供与创新实验室的协作以及访问卓越中心的机会,以更深入地了解人工智能解决方案。
富士通
富士通提供系统、解决方案和专业知识的完美结合,以保证最大的生产力、效率和灵活性,从而提供信心和可靠性。自2020年以来,我们一直积极参与并提交数据中心和边缘部门的推理和训练轮次。
在这一轮中,我们使用两个系统向数据中心封闭部门提交了参赛作品。第一个系统是 PRIMERGY CDI,配备安装在外部 PCIe BOX 中的 16xL40S。第二个系统是GX2560M7,服务器内部配备4xH100-SXM。我们还使用 PRIMERGY CDI 向数据中心封闭式电力部门提交了参赛作品。
通过在三个外部 PCI-BOX 中安装多达 20 个 GPU,PRIMERGY CDI 可以用作单个节点。此外,系统配置可以根据训练和推理工作负载的大小进行调整。在这一轮中,我们在PRIMERGY CDI系统上安装了16xL40S并运行稳定的扩散和gptj。测量结果如下图所示。我们使用配备多个L40S的系统确认了如图所示的性能。
我们的目标是通过创新建立社会信任,使世界更加可持续发展。凭借推动创新和专业知识的丰富传统,我们致力于为社会和尊贵客户的发展做出贡献。因此,我们将继续满足客户的需求,并努力通过 MLCommons 的活动提供有吸引力的服务器系统。
Giga Computing
技嘉科技全资子公司,是从技嘉科技分拆出来的企业单位,设计、制造和销售服务器、服务器主板、沉浸式解决方案和工作站。
作为 MLCommons 的创始成员之一,GigaComputing 持续支持社区为各种人工智能训练和推理工作负载对服务器解决方案进行基准测试的努力。继上一次 v3.1 推理基准测试之后,GigaComputing 在最新一轮的 MLPerf Inference v4.0 中提交了强大的 GIGABYTE G593-SD1 系统,该系统配置了最新的第五代 Intel Xeon 可扩展处理器和八个 NVIDIA H100 SXM5 GPU。该系统具有高数据带宽和精心优化的数据处理配置。结果不言而喻,展示了极高的效率,同时在所有基准测试任务中保持了顶级性能。我们在最新基准测试中取得的优异成绩凸显了我们对提供顶级功能和优化的承诺。
我们千兆计算的重点是持续改进,我们为系统评估提供远程测试和公共基准就是例证。我们致力于提高效率并开创先进的冷却技术,例如浸入式和 DLC,以应对即将到来的功耗激增。请继续关注,我们将继续通过千兆计算突破卓越计算的界限。
谷歌云
NVIDIA GPU 与 Google Cloud 的基础设施技术相结合,提供业界领先的规模和性能。 8 月份,我们宣布A3 虚拟机现已全面上市; A3 由单个虚拟机中的 NVIDIA 8 H100 Tensor Core GPU 提供支持,专为训练和服务要求苛刻的新一代 AI 工作负载和法学硕士而设计。 A3 能够通过达到 26 exaflops 的 AI 性能来达到超级计算能力。
对于 MLPerf Inference v4.0 基准测试,Google 提交了 20 个结果,包括使用 A3 VM 的新 Stable Diffusion XL 和 Llama 2 (70B) 结果。 Stable Diffusion XL 和 Llama 2 结果与 NVIDIA 提交的材料所展示的峰值性能相差 1-4% 以内。强劲的 A3 VM 结果证明了 Google Cloud 与 NVIDIA 的密切合作关系,专门为法学硕士和新一代人工智能构建工作负载优化的端到端解决方案。
惠普
慧与 (HPE) 与 NVIDIA、高通和 KRAI 合作成功提交了结果,展示了一系列适用于数据中心的计算机视觉 (CV)、自然语言处理 (NLP)、生成人工智能 (GenAI) 的高性能推理系统,以及大型语言模型(LLM)。 HPE 服务器性能结果包含在数据中心封闭、数据中心开放和数据中心网络部门中。
HPE 提交了这些系统上的 AI 推理结果:
· HPE Cray 超级计算 (SC) XD670(配备 8 个 NVIDIA H100 SXM 80GB,700W TDP*)
· HPE ProLiant DL380a Gen11 服务器(配备 4 个 NVIDIA H100 PCIe 80GB、400W TDP*)
· HPE ProLiant DL380a Gen11 服务器(配备 4 个 NVIDIA L40S PCIe 48GB、300W TDP*)
· HPE ProLiant DL380a Gen11 服务器(配备 8 个 Qualcomm Cloud AI 100 Ultra 128GB、150W TDP*)
亮点包括:
· 配备 NVIDIA H100 SXM 的 HPE Cray SC XD670 在 Bert 99.0 离线场景下展示了 NLP 的最高性能结果
· 配备 4 个 NVIDIA H100 PCIe 的 HPE ProLiant DL380a 在 Llama2 70B 型号上展示了对于四个或更少 PCIe 连接 GPU 的最高性能结果。
· 配备 4 个 NVIDIA L40S 的 HPE ProLiant DL380a 在用于 CV、NLP、GenAI 和 LLM 的同类 GPU 中展示了良好的性能。
· HPE 在 HPE ProLiant DL380a Gen11 服务器中使用 8 个 Qualcomm Cloud AI 100 Ultra 加速器提交了第一个关于 CV 和 NLP 的 MLPerf 推理预览结果。
非常感谢 KRAI 的合作,为 Qualcomm Cloud AI 100 Ultra 加速器实现了高性能和高能效。
英特尔
英特尔提交了英特尔 Gaudi 2 AI 处理器的 MLPerf Inference v4.0 结果,并首次提交了第五代至强可扩展处理器。结果表明,英特尔致力于提供全系列人工智能产品,以满足广泛的客户人工智能需求。
英特尔 Gaudi 2 加速器是一款 7 纳米处理器,在 MLPerf Inference 上为最先进的模型提供了可靠的性能结果。在 Stable Diffusion XL 上,Gaudi 2 加速器的每秒离线采样数和每秒服务器查询数分别为 6.26 和 6.25,对于 LLama v2-70B,每秒离线令牌数和服务器令牌数为 8035.0 和 6287.5,分别。鉴于客户对 Hugging Face TGI(文本生成接口)的强烈需求,英特尔使用支持连续批处理和张量并行的 TGI 服务工具包提交了 LLama 结果,从而提高了实际 LLM 扩展的效率。英特尔 Gaudi 软件套件不断扩大对我们最高客户需求的法学硕士和多模式模型的覆盖范围。
英特尔仍然是唯一提交 MLPerf 结果的 CPU 供应商。英特尔已从 2020 年开始提交四代至强产品的 MLPerf 结果。英特尔提交的带有英特尔高级矩阵扩展 (AMX) 的第五代英特尔至强可扩展处理器表明 CPU 对于通用 AI 工作负载具有出色的性能。由于硬件和软件的改进,去年在 MLPerf Inference v3.1 中,英特尔第五代至强的结果比第四代至强的结果提高了 1.42 倍。
对于具有软件优化(包括连续批处理)的 GPT-J,英特尔提交的 Xeon 表现出与 v3.1 提交相比约 1.8 倍的性能提升。同样,由于 MergedEmbeddingBag 和利用 AMX 的其他优化,DLRMv2 显示了约 1.8 倍的性能提升和 99.9 的准确度。
英特尔非常自豪能够与 OEM 合作伙伴(思科、戴尔、广达、Supermicro 和 WiWynn)合作交付他们自己的 MLPerf 提交文件。
通过持续的软件更新和优化,英特尔预计其加速器和 CPU 的性能和生产力将持续进步。
瞻博网络
对于 MLPerf Inference 4.0,瞻博网络提交了一套针对 Llama 2 的测试,该模型具有 700 亿参数的大语言模型 (LLM),该模型在瞻博网络验证设计 (JVD) 上运行,该设计由脊叶网络拓扑和轨道优化设计组成。多节点数据中心设置由瞻博网络人工智能优化的以太网结构提供支持,包括用于 GPU 间通信的带有 ROCEv2 的 QFX 系列交换。测试和验证是在 Juniper AI 实验室的 NVIDIA A100 和 H100 集群上进行的,具有轨内和轨间组合。这是有史以来第一次向 MLCommons 提交多节点以太网。
瞻博网络很高兴与 MLCommons 合作,加速人工智能 (AI) 创新,让世界各地的公司能够更简单、更快、更经济地部署 AI 数据中心基础设施。 LLama 等生成式 AI 突破了计算、存储和网络系统的性能界限。训练这些模型是一个巨大的并行处理问题,依赖于强大的网络解决方案。 AI 工作负载具有独特的特征,并对网络提出了新的要求,但解决此类严峻挑战正是瞻博网络 25 年来一直在做的事情。人工智能集群基础设施要从早期阶段走向大众市场,必须利用开放技术来发挥产业生态的集体力量和创新能力。
瞻博网络致力于采用运营优先的方法,利用基于意图的网络、AIOps 和 800Gb 以太网方面的市场领先功能,帮助客户管理整个 AI 数据中心网络生命周期。以太网和我们的 Apstra 数据中心结构自动化软件等开放技术消除了供应商锁定,利用行业生态系统来降低成本并推动创新,并支持跨 AI 训练、推理、存储和管理网络的通用网络操作。此外,经过严格的预先测试和验证的设计(例如瞻博网络提交给 MLCommons 的设计)对于确保客户能够自行部署安全的数据中心基础设施至关重要。
KRAI
KRAI 于 2020 年在“Silicon Fen”(英国剑桥)成立,是为设计超高效且经济高效的人工智能计算机系统而量身定制的优质基准测试和优化解决方案的供应商。 KRAI 团队参加了全部 9 轮 MLPerf 推理轮,自 2019 年以来,在 60 多名提交者中,只有另外三名提交者实现了这一壮举。
v4.0 轮融资标志着高通和 KRAI 之间长达三年的密切合作。为了庆祝这一时刻,我们专注于通过本轮预览的 Cloud AI 100 Ultra 加速器取得出色的成果。特别是,配备 16 个单宽 Ultra 加速器的 GIGABYTE G293-Z43 2U 服务器在 ResNet50 上每秒提供超过 900,000 个样本,在 RetinaNet 上每秒提供近 15,500 个样本。每个 Ultra 加速器具有 64 个 AI 核心,这一成就代表着单个系统中线性扩展至 1,024 个 AI 核心,之前的最高成就是 288 个核心(包含 18 个 Pro 加速器)。超高性能、高效和可扩展推理的魔力/源已作为广受好评的 KRAI 推理库技术 (KILT) 代码库的新公开版本与社区共享。在这一轮中,Qualcomm、KRAI、HPE、Dell、Lenovo 和 CTuning 提交的材料中使用了 KILT。
作为 KRAI 的另一个值得骄傲的时刻,我们与 Google 合作,使用最新一代张量处理单元复制和优化 LLM 提交的内容。欢迎 Google Cloud 客户使用 KRAI X 技术自动化的工作流程重现 TPU-v5e 结果。
我们感谢 HPE 提供对配备 8 个 Cloud AI 100 标准加速器和 200GbE 网络设备的 ProLiant DL385 服务器的访问,这使得本轮中唯一的网络封闭提交成为可能。至关重要的是,上一轮从 10GbE 进行的网络升级使我们能够扩展对带宽要求更高的 RetinaNet 基准测试,以及带宽较少的 BERT 基准测试。
联想
联想致力于为所有人提供更智能的技术解决方案,包括硬件、软件等。为了实现这一目标,我们使用 MLPerf Inference v.4.0 进行研究和测试,使我们能够展示我们在基准测试方面的领先成果。
通过与 MLCommons 的合作,联想能够每季度通过 MLPerf 基准测试展示这些结果。我们与 NVIDIA 和 Intel 在图像分类、医学图像分割、语音转文本和自然语言处理等重要 AI 任务上的合作使我们取得了领先的成果。
我们很自豪能够使用配备 2 个 NVIDIA L4 的 ThinkSystem SE360 以及配备 2 个 NVIDIA L40 边缘服务器的 SE450 和 SE455 来完成这些任务。这些合作使我们能够根据领先的基准不断为客户改进技术。
我们与 MLCommons 的合作关系为我们如何与竞争对手进行比较提供了宝贵的见解,设定了客户期望,并使我们能够不断增强我们的产品。通过这种合作,我们可以与行业专家密切合作,创造增长并最终为我们的客户提供更好的产品,这是我们的首要任务。
英伟达
我们很高兴能够在 MLPerf Inference v4.0 中展示 NVIDIA 加速计算平台令人难以置信的推理性能。 NVIDIA HGX H100 平台集成了多达 8 个具有高速互连功能的 H100 Tensor Core GPU,借助我们的 TensorRT-LLM 软件,与上一轮测试相比,GPT-J 测试的性能提高了近 3 倍。该推理优化器和运行时通过开源模块化 Python API 提高了易用性和可扩展性,用于随着法学硕士的发展定义、优化和执行新的架构和增强功能。
我们还很高兴能够使用 NVIDIA HGX H200 AI 超级计算平台(由最新的 H200 Tensor Core GPU 提供支持)首次提交作品。 HGX H200 采用高性能定制散热解决方案,在新的 Llama 2 70B LLM 测试中,性能比 HGX H100 高出 45%。而且,NVIDIA GH200 Grace Hopper 超级芯片将 NVIDIA Grace CPU 与 NVIDIA Hopper GPU 结合在一个多功能、易于部署的模块中,将 H100 GPU 的卓越性能扩展到法学硕士、文本到图像生成 AI 和推荐人。
NVIDIA AI 平台在整个技术堆栈中提供创新,端到端加速整个 AI 工作流程(从数据准备到模型训练,再到从云端到边缘的部署推理),并在各种 AI 模型中实现出色的性能。各大云和服务器制造商也提供该服务,并通过 NVIDIA AI Enterprise 提供生产 AI 和企业级支持的最快路径。
我们很高兴看到 14 家 NVIDIA 合作伙伴(包括华硕、Azure、Broadcom、思科、戴尔、富士通、GigaComputing、Google、HPE、联想、甲骨文、广达云技术、Supermicro 和 Wiwynn)提交了出色的推理结果,并且都在本地进行以及涵盖 NVIDIA 数据中心 GPU 产品组合的云解决方案。
我们还希望赞扬 MLCommons 正在开展的工作,将基准测试最佳实践引入计算领域,从而对 AI 和 HPC 平台进行同行评审的同类比较,以更好地了解和比较不同工作负载的产品性能。
甲骨文
Oracle 云基础设施 (OCI) 在我们的融合应用程序中提供人工智能基础设施、生成式人工智能、人工智能服务、机器学习服务和人工智能。我们的 AI 基础设施产品组合包括由 NVIDIA H100、NVIDIA A100 和 NVIDIA A10 GPU 提供支持的裸机实例和虚拟机。
高端 BM.GPU.H100.8 实例的推理基准测试结果表明,OCI 提供的高性能至少与本地和云基础设施的其他部署相匹配。这些实例为每个节点提供八个 NVIDIA GPU。除了推理之外,对于训练工作负载,每个节点还可以使用高性能 RDMA 网络对数万个 GPU 进行集群。
截至 2024 年 3 月,OCI 的 BM.GPU.H100.8 实例通过 OCI 上的 NVIDIA GPU 提供最高可用性能。
云达科技
广达云科技 (QCT) 是一家支持多样化 HPC 和 AI 工作负载的全球数据中心解决方案提供商,在 MLCommons 发布的最新 MLPerf 结果中被列入 MLPerf 推理列表。
QCT参加了最新一轮的MLPerf Inference v4.0并向数据中心封闭部门提交了结果,包括针对不同系统配置的稳定扩散和llama2的新模型。
其中一项展示的配置采用了 QCT 的尖端平台,即新推出的带有 NVIDIA Grace Hopper Superchip 的 QuantaGrid S74G-2U。通过 NVLink C2C 互连,CPU 和 GPU 之间的一致性内存可以改善内存密集型 AI 推理。 QCT在数据中心类别的多项AI任务中取得了出色的表现。
QuantaGrid D54U-3U是一款专为AI/HPC设计的加速服务器。该 3U 系统支持两个第五代英特尔至强可扩展处理器,支持四个双宽加速卡或最多八个单宽加速卡,提供针对各种 AI/HPC 应用进行优化的全面而灵活的架构。这次,QCT 分别使用四张 NVIDIA H100 PCIe 卡和四张 NVIDIA L40S PCIe 卡验证了结果。
另一种配置展示了 QCT 的 QuantaGrid D54X-1U 与仅 CPU 推理场景中的英特尔至强可扩展处理器。 QCT 的仅 CPU 配置的服务器经过验证,能够在采用 Intel AMX 指令集的通用 AI 工作负载中表现出色。
展望未来,QCT 仍致力于为学术和工业用户提供全面的硬件系统、解决方案和服务。该公司将继续与 MLCommons 社区分享其 MLPerf 结果,为 MLPerf 推理和训练基准的进步做出贡献。
高通
高通云人工智能推理加速器利用公司在高级信号处理和能效方面的专业知识,在数据中心和边缘环境中提供高吞吐量、低功耗的人工智能推理处理。
在v4.0轮次中,高通推出了AI推理加速器Cloud AI 100 Ultra,并提交了“封闭预览”模式评估。 Cloud AI 100 Ultra 的早期预览结果展示了其在低功耗下的卓越性能,其在 ML 基准测试中的性能证明了这一点。与 Cloud AI 100 Pro 提交的内容相比,所有 Cloud AI 100 Ultra 提交的内容均表现出 2.5 至 3 倍的性能提升,同时每个加速器的功耗低于 150W。除了 NLP 和计算机视觉网络之外,我们还引入了 GenAI Stable Diffusion XL 提交。我们的合作伙伴戴尔、HPE 和联想也提交了 Cloud AI 100 Ultra 卡的预览结果。
在 Cloud AI 100 中,CTuning 首次使用由 8 个 Cloud AI 100 标准加速器提供支持的 Amazon EC2 DL2q 云实例提交结果,实现了与独立服务器相当的性能。 CTuning 还使用由 4 个 Cloud AI 100 Pro 加速器提供支持的 Cirrascale Quad AI 100 Cloud 实例提交了 MLPerf 基准测试,取得了与独立系统相当的结果。
高通的 MLPerf Inference v4.0 结果在所有类别的峰值离线性能和能效方面都超越了其之前的记录。 2U 数据中心服务器平台配备 16 个 Qualcomm Cloud AI 100 Ultra 加速器(150W TDP),在预览模式下实现了超过 902K ResNet50 inf/秒的令人印象深刻的吞吐量。它还创下了新的高能效,ResNet50 达到 275 QPS/Watt,RetinaNet 达到 5.2 QPS/Watt,BERT 达到 10.2 QPS/Watt。
高通提交的这些结果是通过使用 KRAI 的 X 和 KILT 技术实现的。 Qualcomm 和 Snapdragon 是高通公司的商标或注册商标。 Qualcomm Cloud AI 和 Snapdragon 是 Qualcomm Technologies, Inc. 和/或其子公司的产品。
红帽+超微
大规模 AI 数据中心基础设施建设者 Supermicro 和全球领先的企业开源解决方案提供商 Red Hat Inc 合作提交了首个 Red Hat OpenShift AI MLPerf Inference v4.0。红帽 OpenShift AI 是一个灵活、可扩展的 MLOps 平台,提供用于构建、部署和管理支持 AI 的应用程序的工具。
GPU A+ 服务器,AS-4125GS-TNRT具有灵活的 GPU 支持和配置选项:具有主动和被动 GPU,以及最多 10 个双宽、全长 GPU 的双根或单根配置。此外,双根配置具有直接连接 8 个 GPU 的功能,无需 PLX 交换机,可实现尽可能低的延迟并提高性能,这对于我们的客户面临的 AI 和 HPC 工作负载的苛刻场景非常有利。
红帽 OpenShift 让您的 AI/ML 工作负载的创建、调度和监控变得更轻松、更安全。 OpenShift Operators 发现、配置和监控您的 GPU、存储设备和网络设备,提供易用性、灵活性和安全性。
红帽 OpenShift AI 是一个灵活、可扩展的 MLOps 平台,提供用于构建、部署和管理支持 AI 的应用程序的工具。它使用开源技术构建,为团队提供值得信赖、操作一致的功能来进行实验、服务模型和交付创新应用程序。红帽 OpenShift AI(以前称为红帽 OpenShift Data Science)支持本地和公共云中的 AI/ML 实验和模型的整个生命周期。
此提交展示了 OpenShift AI 模型服务堆栈的灵活性,可通过使用自定义运行时功能来支持 vLLM 等开源 LLM 运行时。我们还感到自豪的是,我们是本轮中唯一在 Nvidia GPU 上使用 vLLM 提交 GPT-J-6b 和 llama-2-70b 结果的结果,无需任何量化或模型编译。
SiMa
SiMa.ai 引领边缘人工智能技术,在性能和能源效率方面树立了新标准。我们很高兴在这份最新的 MLPerf 基准测试报告中分享我们的结果,与 2023 年 8 月提交的报告相比,我们在所有类别中的 FPS 提高了 7% 到 16%。
在边缘人工智能领域,有限的功率和苛刻的任务不断在功率和效率之间造成紧张,我们能够在 FPS 方面取得巨大进步,同时仍然提高我们之前提交的 MLPerf 3.1 中所有工作负载的 FPS/W。该指标是我们的系统每消耗一瓦电量可以处理多少帧的关键指标。
我们的 FPS 提升,尤其是在 SingleStream 模式下超过 16%,是 MLPerf v4.0 提交中最令人印象深刻的结果之一,因为批次 1 性能的 SingleStream 是实际应用程序中的主要工作负载。这得益于 MLA Runtime 平台软件在优化端到端模型执行方面的显着增强。我们进步的真正力量在于将这些超越基准的改进转化为我们客户的现实利益。他们体验到所有模型的性能显着增强,在广泛的边缘人工智能应用中释放了新的价值水平。
SiMa.ai 在 MLPerf 中的参与和表现是更广泛增长战略的一部分,我们正在为当今和下一代更快、更强大的解决方案铺平道路。我们不仅仅是进行技术升级;这是一次战略飞跃,巩固了我们在边缘人工智能性能、效率和创新方面的领导地位。
Supermicro
美超微在人工智能基础设施解决方案方面表现出色,在 MLPerf Inference v4.0 竞赛中展示了卓越的表现,在数据中心推理类别的封闭和开放组别中提交了参赛作品。
Supermicro 的使命是为各种工作负载提供应用优化的系统。一个突出的例子是 SYS-821GE-TNHR,这是一款专为 NVIDIA HGX H100 8-GPU 平台设计的可定制解决方案。该系统通过我们的构建块方法量身定制,可满足客户的特定要求和工作负载需求。此外,我们现在为最新的基于 NVIDIA HGX 的系统以及基于 PCIe 的系统提供液体冷却选项,使部署能够利用更高 TDP 的 CPU 和 GPU,而无需进行热节流。
我们的 GPU 服务器经过精心设计,可以有效处理大型数据集和高要求的工作负载。它们可以加快存储访问速度、减少延迟并提高存储带宽,从而提高工作效率并加快任务完成速度。利用 NVIDIA GPU 和本地 DMA 和 RDMA 等高级访问方法,以及通过多个 NIC 和交换机的高性能网络,Supermicro GPU 服务器在 AI、机器学习和 HPC 任务中表现出色。
SYS-521GE-TNRT服务器配备L40S GPU,通过PCIe 5.0双根交换机支持多达10个基于PCIe的GPGPU,提供卓越的处理能力。 L40S GPU 配备 48GB GDDR6 显存,理论性能高达 91.6 TFLOP,针对 AI 媒体和图形应用进行了优化,对于高性能计算任务而言具有无可比拟的价值。此外,该配置还配备双第四代英特尔至强可扩展处理器、高达 8TB 的内存容量以及带有 24 个热插拔 NVMe/SATA/SAS 驱动器托架的充足存储选项,为密集型计算任务提供可扩展性和效率。
Supermicro 为任何环境提供各种 GPU 系统,在多个 MLPerf 基准测试中始终如一地提供高性能。展望未来,我们仍然致力于微调我们的系统,为客户提供优化的体验和性能。
Wiwynn
Wiwynn是一家领先的超大规模数据中心云 IT 基础设施提供商。我们主要感兴趣的领域包括云、人工智能、5G 和边缘计算的进步。特殊的是,我们为包括人工智能在内的广泛应用生产高质量的服务器。
在最新一轮的MLPerf Inference v4.0测试中,Wiwynn提交了边缘和数据中心两个类别的ES200G2基准测试结果。 Wiwynn ES200G2是一款2U服务器,专为满足电信使用的各种需求而定制,包括边缘应用、用于5G服务管理的推理主机和数据中心。
在边缘类别中,我们对配备两个 NVIDIA L40S GPU 的 ES200G2 进行了基准测试,适用于图像识别或其他 AI 应用等边缘应用。在数据中心类别中,我们对配备英特尔第五代至强处理器的ES200G2进行了基准测试,该处理器可以组成服务器池来执行各种任务。这两项结果都表明该平台能够运行流行的人工智能框架并取得良好的性能。
Wiwynn的企业使命是“提供从边缘到云的最佳 TCO、工作负载和能源优化 IT 解决方案”。 Wiwynn将继续朝着这个目标努力,并参与社区活动。我们对创新和卓越的承诺体现在我们参与 MLPerf Inference v4.0 等行业基准测试中,我们努力展示我们产品的功能并为该领域的进步做出贡献。
本文转载自微信公众号“半导体行业观察”,智通财经编辑:陈宇锋。




